隨著物聯網、移動互聯網和工業互聯網的迅猛發展,數據正以前所未有的速度和規模產生。海量流數據處理,即對持續不斷、高速生成的數據流進行實時或近實時分析與處理,已成為驅動企業智能決策和業務創新的關鍵技術。在這一背景下,將海量流數據處理能力進行服務化封裝,構建標準化、可復用、易擴展的數據處理服務,正成為產業界與學術界共同關注的焦點。
一、 海量流數據處理的核心挑戰
傳統的批處理模式在面對海量、實時、無序的數據流時顯得力不從心。流數據處理面臨吞吐量、延遲、準確性、狀態管理和容錯性等多重挑戰。如何設計一個能夠持續穩定運行、低延遲處理海量事件、并能保證結果準確性的系統,是首要難題。
二、 服務化:數據處理能力的新范式
“服務化”的核心思想是將復雜的技術能力封裝成標準化的、通過網絡接口(API)進行訪問的服務。將海量流數據處理能力服務化,意味著:
- 解耦與復用:將數據接入、清洗、轉換、分析、輸出等處理邏輯封裝成獨立服務,業務應用無需關心底層復雜的技術實現,只需通過API調用所需的數據處理功能,極大地提升了開發效率和系統可維護性。
- 彈性與可擴展:服務化的架構天然支持水平擴展。面對波動的數據流量,可以動態調整服務實例的數量,實現資源的彈性伸縮,既保障了處理性能,又優化了成本。
- 標準化與集成:統一的API接口和協議(如RESTful、gRPC)使得不同團隊、不同系統能夠輕松集成和使用流數據處理能力,促進了企業內部的數據協作與生態構建。
- 運維與治理:集中的服務管理平臺可以方便地對數據處理服務進行監控、告警、版本管理和生命周期控制,提升了整體系統的可靠性與可運維性。
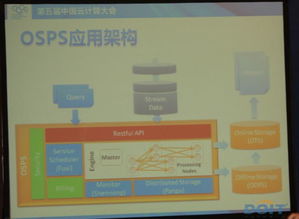
三、 數據處理服務化的關鍵技術架構
一個成熟的海量流數據處理服務化平臺通常包含以下層次:
- 基礎設施層:提供計算、存儲和網絡資源,通常基于云原生技術(如Kubernetes)實現資源的動態調度與管理。
- 流處理引擎層:集成或自研核心流處理引擎(如Apache Flink、Spark Streaming、Kafka Streams),負責高吞吐、低延遲的數據處理計算。
- 服務化封裝層:這是實現“服務化”的關鍵。它將流處理作業(Job)抽象為“服務”。通過定義服務模板、配置處理邏輯(如SQL、UDF或自定義代碼)、指定輸入輸出源(如Kafka、MQTT、數據庫),將一個數據處理流水線打包成一個可部署、可調度的服務實例。
- API網關與管理控制層:對外提供統一的API訪問入口,負責認證、鑒權、限流和路由。對內提供可視化的控制臺,用于服務的設計、部署、啟停、監控和運維。
- 數據源與輸出集成層:提供豐富的連接器(Connectors),支持與各類消息隊列、數據庫、文件系統和外部API進行無縫數據對接。
四、 實踐場景與價值體現
數據處理服務化已在眾多場景中發揮巨大價值:
- 實時風控:在金融交易或在線支付中,將交易數據流實時送入風控規則服務,毫秒級內識別并阻斷欺詐行為。
- 物聯網監控:對百萬級設備上報的傳感數據流進行實時聚合與分析服務,即時發現設備異常并預警。
- 實時推薦:將用戶點擊、瀏覽行為流與模型預估服務結合,實現動態的個性化內容推薦。
- 運營大盤:將各業務線的日志和事件流通過數據清洗、聚合服務,實時生成可視化的業務運營儀表盤。
在這些場景中,服務化模式使得業務團隊能夠像“點菜”一樣,快速組合和調用所需的數據處理功能,將開發周期從周/月級縮短至天/小時級,真正讓數據能力賦能業務敏捷創新。
五、 未來展望
海量流數據處理的服務化將朝著更智能、更融合的方向演進:
- Serverless化:進一步抽象底層資源,開發者只需關注數據處理邏輯,平臺實現完全的自動擴縮容與按需計費。
- AI融合:將機器學習模型的訓練與推理過程無縫嵌入流處理服務鏈,實現實時智能決策。
- 統一批流服務:提供統一的API和服務框架,讓用戶無需區分批處理和流處理,實現真正的一體化數據處理體驗。
以孫冰等專家和從業者為代表的探索與實踐表明,將海量流數據處理能力服務化,不僅是應對當前數據挑戰的有效手段,更是構建未來企業智能化數據基礎設施的基石。它通過降低技術門檻、提升開發運維效率,最終目標是讓數據如水、電一般,成為隨時可取、隨處可用的基礎服務,源源不斷地驅動業務價值創造。